2.2. Linux Performance Tools: CPU
Here begins our discussion of performance tools that enable you to extract information previously described.
2.2.1. vmstat (Virtual Memory Statistics)
vmstat stands for virtual memory statistics, which indicates that it will give you information about the virtual memory system performance of your system. Fortunately, it actually does much more than that. vmstat is a great command to get a rough idea of how your system performs as a whole. It tells you
- How many processes are running
- How the CPU is being used
- How many interrupts the CPU receives
- How many context switches the scheduler performs
It is an excellent tool to use to get a rough idea of how the system performs.
2.2.1.1 CPU Performance- Related Options
vmstat can be invoked with the following command line:
vmstat [-n] [-s] [delay [count]]
vmstat can be run in two modes: sample mode and average mode. If no parameters are specified, vmstat stat runs in average mode, wherevmstat displays the average value for all the statistics since system boot. However, if a delay is specified, the first sample will be the average since system boot, but after that vmstat samples the system every delay seconds and prints out the statistics. Table 2-1 describes the options that vmstat accepts.
Table 2-1. vmstat Command-Line Options
Option | Explanation |
|---|---|
-n | By default, vmstat periodically prints out the column headers for eachperformance statistic. This option disables that feature so that after the initial header, only performance data displays. This proves helpful if you want to import the output of vmstat into a spreadsheet. |
-s | This displays a one-shot details output of system statistics that vmstatgathers. The statistics are the totals since the system booted . |
delay | This is the amount of time between vmstat samples. |
vmstat provides a variety of different output statistics that enable you to track different aspects of the system performance. Table 2-2 describes those related to CPU performance. The next chapter covers those related to memory performance.
Table 2-2. CPU-Specific vmstat Output
Column | Explanation |
|---|---|
r | This is the number of currently runnable processes. These processes are not waiting on I/O and are ready to run. Ideally, the number of runnable processes would match the number of CPUs available. |
b | This is the number of processes blocked and waiting for I/O to complete. |
forks | The is the number of times a new process has been created. |
in | This is the number of interrupts occurring on the system. |
cs | This is the number of context switches happening on the system. |
us | The is the total CPU time as a percentage spent on user processes (including "nice" time). |
sy | The is the total CPU time as a percentage spent in system code. This includes time spent in the system , irq , and softirq state. |
wa | The is the total CPU time as a percentage spent waiting for I/O. |
id | The is the total CPU time as a percentage that the system is idle. |
vmstat provides a good low-overhead view of system performance. Because all the performance statistics are in text form and are printed to standard output, it is easy to capture the data generated during a test and process or graph it later. Because vmstat is such a low-overhead tool, it is practical to keep it running on a console or in a window even on a very heavily loaded server when you need to monitor the health of the system at a glance.
2.2.1.2 Example Usage
As shown in Listing 2.2, if vmstat is run with no command-line parameters, it displays the average values for the statistics that it records since the system booted. This example shows that the system was nearly idle since boot, as indicated by the CPU usage columns , under us , sys , wa , and id . The CPU spent 5 percent of the time since boot on user application code, 1 percent on system code, and the rest, 94 percent sitting idle.
Listing 2.2.
[ezolt@scrffy tmp]$ vmstat procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 181024 26284 35292 503048 0 0 3 2 6 1 5 1 94 0
Although vmstat 's statistics since system boot can be useful to determine how heavily loaded the machine has been, vmstat is most useful when it runs in sampling mode, as shown in Listing 2.3. In sampling mode, vmstat prints the systems statistics after the number of seconds passed with the delay parameter. It does this sampling count a number of times. The first line of statistics in Listing 2.3 contains the system averages since boot, as before, but then the periodic sample continues after that. This example shows that there is very little activity on the system. We can see that no processes were blocked during the run by looking at the 0 in the b . We can also see, by looking in the r column, that fewer than 1 processes were running when vmstat sampled its data.
Listing 2.3.
[ezolt@scrffy tmp]$ vmstat 2 5 procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 181024 26276 35316 502960 0 0 3 2 6 1 5 1 94 0 1 0 181024 26084 35316 502960 0 0 0 0 1318 772 1 0 98 0 0 0 181024 26148 35316 502960 0 0 0 24 1314 734 1 0 98 0 0 0 181024 26020 35316 502960 0 0 0 0 1315 764 2 0 98 0 0 0 181024 25956 35316 502960 0 0 0 0 1310 764 2 0 98 0
vmstat is an excellent way to record how a system behaves under a load or during a test condition. You can use vmstat to display how the system is behaving and, at the same time, save the result to a file by using the Linux tee command. (Chapter 8, "Utility Tools: Performance Tool Helpers," describes the tee command in more detail.) If you only pass in the delay parameter, vmstat will sample indefinitely. Just start it before the test, and interrupt it after the test has completed. The output file can be imported into a spreadsheet, and used to see how the system reacts to the load or various system events. Listing 2.4 shows the output of this technique. In this example, we can look at the interrupt and context switches that the system is generating. We can see the total number of interrupts and context switches in the in and cs columns respectively.
The number of context switches looks good compared to the number of interrupts. The scheduler is switching processes less than the number of timer interrupts that are firing. This is most likely because the system is nearly idle, and most of the time when the timer interrupt fires, the scheduler does not have any work to do, so it does not switch from the idle process.
(Note: There is a bug in the version of vmstat that generated the following output. It causes the system average line of output to display incorrect values. This bug has been reported to the maintainer of vmstat and will be fixed soon, hopefully.)
Listing 2.4.
[ezolt@scrffy ~/edid]$ vmstat 1 | tee /tmp/output procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 0 1 201060 35832 26532 324112 0 0 3 2 6 2 5 1 94 0 0 0 201060 35888 26532 324112 0 0 16 0 1138 358 0 0 99 0 0 0 201060 35888 26540 324104 0 0 0 88 1163 371 0 0 100 0 0 0 201060 35888 26540 324104 0 0 0 0 1133 345 0 0 100 0 0 0 201060 35888 26540 324104 0 0 0 60 1174 351 0 0 100 0 0 0 201060 35920 26540 324104 0 0 0 0 1150 408 0 0 100 0 [Ctrl-C]
More recent versions of vmstat can even extract more detailed information about a grab bag of different system statistics, as shown in Listing 2.5.
The next chapter discusses the memory statistics, but we look at the CPU statistics now. The first group of statistics, or "CPU ticks ," shows how the CPU has spent its time since system boot, where a "tick" is a unit of time. Although the condensed vmstat output only showed four CPU states—us , sy , id , and wa —this shows how all the CPU ticks are distributed. In addition, we can see the total number of interrupts and context switches. One new addition is that of forks , which is basically the number of new processes that have been created since system boot.
Listing 2.5.
[ezolt@scrffy ~/edid]$ vmstat -s 1034320 total memory 998712 used memory 698076 active memory 176260 inactive memory 35608 free memory 26592 buffer memory 324312 swap cache 2040244 total swap 201060 used swap 1839184 free swap 5279633 non-nice user cpu ticks 28207739 nice user cpu ticks 2355391 system cpu ticks 628297350 idle cpu ticks 862755 IO-wait cpu ticks 34 IRQ cpu ticks 1707439 softirq cpu ticks 21194571 pages paged in 12677400 pages paged out 93406 pages swapped in 181587 pages swapped out 1931462143 interrupts 785963213 CPU context switches 1096643656 boot time 578451 forks
vmstat provides a broad range of information about the performance of a Linux system. It is one of the core tools to use when investigating a problem with a system.
2.2.2. top (v. 2.0.x)
top is the Swiss army knife of Linux system-monitoring tools. It does a good job of putting a very large amount of system-wide performance information in a single screen. What you display can also be changed interactively; so if a particular problem creeps up as your system runs, you can modify what top is showing you.
By default, top presents a list, in decreasing order, of the top CPU-consuming processes. This enables you to quickly pinpoint which program is hogging the CPU. Periodically, top updates the list based on a delay that you can specify. (It is initially 3 seconds.)
2.2.2.1 CPU Performance-Related Options
top is invoked with the following command line:
top [d delay] [C] [H] [i] [n iter] [b]
top actually takes options in two modes: command-line options and runtime options. The command-line options determine how top displays its information. Table 2-3 shows the command-line options that influence the type and frequency of the performance statistics that top displays.
Table 2-3. top Command-Line Options
Option | Explanation |
|---|---|
d delay | Delay between statistic updates. |
n iterations | Number of iterations before exiting. top updates the statisticsiterations times. |
i | Don't display processes that aren't using any of the CPU. |
H | Show all the individual threads of an application rather than just display a total for each application. |
C | In a hyperthreaded or SMP system, display the summed CPU statistics rather than the statistics for each CPU. |
As you run top , you might want to fine-tune what you are observing to investigate a particular problem. The output of top is highly customizable. Table 2-4 describes options that change statistics shown during top 's runtime.
Table 2-4.
Option | Explanation |
|---|---|
f or F | This displays a configuration screen that enables you to select which process statistics display on the screen. |
o or O | This displays a configuration screen that enables you to change the order of the displayed statistics. |
The options described in Table 2-5 turn on or off the display of various system-wide information. It can be helpful to turn off unneeded statistics to fit more processes on the screen.
Table 2-5. top Runtime Output Toggles
Option | Explanation |
|---|---|
l | This toggles whether the load average and uptime information will be updated and displayed. |
t | This toggles the display of how each CPU spends its time. It also toggles information about how many processes are currently running. Shows all the individual threads of an application instead of just displaying a total for each application. |
m | This toggles whether information about the system memory usage will be shown on the screen. By default, the highest CPU consumers are displayed first. However, it might be more useful to sort by other characteristics. |
Table 2-6 describes the different sorting modes that top supports. Sorting by memory consumption is particular useful to figure out which process consumes the most amount of memory.
Table 2-6. top Output Sorting/Display Options
Option | Explanation |
|---|---|
P | Sorts the tasks by their CPU usage. The highest CPU user displays first. |
T | Sorts the tasks by the amount of CPU time they have used so far. The highest amount displays first. |
N | Sorts the tasks by their PID. The lowest PID displays first. |
A | Sorts the tasks by their age. The newest PID is shown first. This is usually the opposite of "sort by PID." |
i | Hides tasks that are idle and are not consuming CPU. |
top provides system-wide information in addition to information about specific processes. Table 2-7 covers these statistics.
Table 2-7. top Performance Statistics
Option | Explanation |
|---|---|
us | CPU time spent in user applications. |
sy | CPU time spent in the kernel. |
ni | CPU time spent in "nice"ed processes. |
id | CPU time spent idle. |
wa | CPU time spent waiting for I/O. |
hi | CPU time spent in the irq handlers. |
si | CPU time spent in the softirq handlers. |
load average | The 1-minute, 5-minute, and 15-minute load average. |
%CPU | The percentage of CPU that a particular process is consuming. |
PRI | The priority value of the process, where a higher value indicates a higher priority. RT indicates that the task has real-time priority, a priority higher than the standard range. |
NI | The nice value of the process. The higher the nice value, the less the system has to execute the process. Processes with high nice values tend to have very low priorities. |
WCHAN | If a process is waiting on an I/O, this shows which kernel function it is waiting in. |
STAT | This is the current status of a process, where the process is either sleeping ( S ), running ( R ), zombied ( killed but not yet dead) ( Z ), in an uninterruptable sleep ( D ), or being traced (T ). |
TIME | The total amount CPU time (user and system) that this process has used since it started executing. |
COMMAND | That command that this process is executing. |
LC | The number of the last CPU that this process was executing on. |
FLAGS | This toggles whether the load average and uptime information will be updated and displayed. |
top provides a large amount of information about the different running processes and is a great way to figure out which process is a resource hog.
2.2.2.2 Example Usage
Listing 2.6 is an example run of top . Once it starts, it periodically updates the screen until you exit it. This demonstrates some of the system-wide statistics that top can generate. First, we see the load average of the system over the past 1, 5, and 15 minutes. As we can see, the system has started to get busy recently (because doom-3.x86 ). One CPU is busy with user code 90 percent of the time. The other is only spending ~13 percent of its time in user code. Finally, we can see that 73 of the processes are sleeping, and only 3 of them are currently running.
Listing 2.6.
catan> top 08:09:16 up 2 days, 18:44, 4 users, load average: 0.95, 0.44, 0.17 76 processes: 73 sleeping, 3 running, 0 zombie, 0 stopped CPU states: cpu user nice system irq softirq iowait idle total 51.5% 0.0% 3.9% 0.0% 0.0% 0.0% 44.6% cpu00 90.0% 0.0% 1.2% 0.0% 0.0% 0.0% 8.8% cpu01 13.0% 0.0% 6.6% 0.0% 0.0% 0.0% 80.4% Mem: 2037140k av, 1132120k used, 905020k free, 0k shrd, 86220k buff 689784k active, 151528k inactive Swap: 2040244k av, 0k used, 2040244k free 322648k cached PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND 7642 root 25 0 647M 379M 7664 R 49.9 19.0 2:58 0 doom.x86 7661 ezolt 15 0 1372 1372 1052 R 0.1 0.0 0:00 1 top 1 root 15 0 528 528 452 S 0.0 0.0 0:05 1 init 2 root RT 0 0 0 0 SW 0.0 0.0 0:00 0 migration/0 3 root RT 0 0 0 0 SW 0.0 0.0 0:00 1 migration/1 4 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 keventd 5 root 34 19 0 0 0 SWN 0.0 0.0 0:00 0 ksoftirqd/0 6 root 34 19 0 0 0 SWN 0.0 0.0 0:00 1 ksoftirqd/1 9 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 bdflush 7 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kswapd 8 root 15 0 0 0 0 SW 0.0 0.0 0:00 1 kscand 10 root 15 0 0 0 0 SW 0.0 0.0 0:00 1 kupdated 11 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 mdrecoveryd
Now pressing F while top is running brings the configuration screen shown in Listing 2.7. When you press the keys indicated (A for PID, B for PPID, etc.), top toggles whether these statistics display in the previous screen. When all the desired statistics are selected, press Enter to return totop's initial screen, which now shows the current values of selected statistics. When configuring the statistics, all currently activated fields are capitalized in the Current Field Order line and have an asterisk (*) next to their name .
Listing 2.7.
[ezolt@wintermute doc]$ top (press 'F' while running) Current Field Order: AbcDgHIjklMnoTP|qrsuzyV{EFW[X Toggle fields with a-z, any other key to return: * A: PID = Process Id B: PPID = Parent Process Id C: UID = User Id * D: USER = User Name * E: %CPU = CPU Usage * F: %MEM = Memory Usage G: TTY = Controlling tty * H: PRI = Priority * I: NI = Nice Value J: PAGEIN = Page Fault Count K: TSIZE = Code Size (kb) L: DSIZE = Data+Stack Size (kb) * M: SIZE = Virtual Image Size (kb) N: TRS = Resident Text Size (kb) O: SWAP = Swapped kb * P: SHARE = Shared Pages (kb) Q: A = Accessed Page count R: WP = Write Protected Pages S: D = Dirty Pages * T: RSS = Resident Set Size (kb) U: WCHAN = Sleeping in Function * V: STAT = Process Status * W: TIME = CPU Time * X: COMMAND = Command Y: LC = Last used CPU (expect this to change regularly) Z: FLAGS = Task Flags (see linux/sched.h) To show you how customizable top is, Listing 2.8 shows a highly configured output screen, which shows only the top options relevant to CPU usage.
Listing 2.8.
08:16:23 up 2 days, 18:52, 4 users, load average: 1.07, 0.92, 0.49 76 processes: 73 sleeping, 3 running, 0 zombie, 0 stopped CPU states: cpu user nice system irq softirq iowait idle total 48.2% 0.0% 1.5% 0.0% 0.0% 0.0% 50.1% cpu00 0.3% 0.0% 0.1% 0.0% 0.0% 0.0% 99.5% cpu01 96.2% 0.0% 2.9% 0.0% 0.0% 0.0% 0.7% Mem: 2037140k av, 1133548k used, 903592k free, 0k shrd, 86232k buff 690812k active, 151536k inactive Swap: 2040244k av, 0k used, 2040244k free 322656k cached PID USER PRI NI WCHAN FLAGS LC STAT %CPU TIME CPU COMMAND 7642 root 25 0 100100 1 R 49.6 10:30 1 doom.x86 1 root 15 0 400100 0 S 0.0 0:05 0 init 2 root RT 0 140 0 SW 0.0 0:00 0 migration/0 3 root RT 0 140 1 SW 0.0 0:00 1 migration/1 4 root 15 0 40 0 SW 0.0 0:00 0 keventd 5 root 34 19 40 0 SWN 0.0 0:00 0 ksoftirqd/0 6 root 34 19 40 1 SWN 0.0 0:00 1 ksoftirqd/1 9 root 25 0 40 0 SW 0.0 0:00 0 bdflush 7 root 15 0 840 0 SW 0.0 0:00 0 kswapd 8 root 15 0 40 0 SW 0.0 0:00 0 kscand 10 root 15 0 40 0 SW 0.0 0:00 0 kupdated 11 root 25 0 40 0 SW 0.0 0:00 0 mdrecoveryd 20 root 15 0 400040 0 SW 0.0 0:00 0 katad-1
top provides an overview of system resource usage with a focus on providing information about how various processes are consuming those resources. It is best used when interacting with the system directly because of the user-friendly and tool-unfriendly format of its output.
2.2.3. top (v. 3.x.x)
Recently, the version of top provided by the most recent distributions has been completely overhauled, and as a result, many of the command-line and interaction options have changed. Although the basic ideas are similar, it has been streamlined, and a few different display modes have been added.
Again, top presents a list, in decreasing order, of the top CPU-consuming processes.
2.2.3.1 CPU Performance-Related Options
top is invoked with the following command line:
top [-d delay] [-n iter] [-i] [-b]
top actually takes options in two modes: command-line options and runtime options. The command-line options determine how top displays its information. Table 2-8 shows the command-line options that influence the type and frequency of the performance statistics that top will display.
Table 2-8. top Command-Line Options
Option | Explanation |
|---|---|
-d delay | Delay between statistic updates. |
-n iterations | Number of iterations before exiting. top updates the statistics'iterations times. |
-i | This option changes whether or not idle processes display. |
-b | Run in batch mode. Typically, top shows only a single screenful of information, and processes that don't fit on the screen never display. This option shows all the processes and can be very useful if you are saving top 's output to a file or piping the output to another command for processing. |
As you run top , you may want to fine-tune what you are observing to investigate a particular problem. Like the 2.x version of top , the output oftop is highly customizable. Table 2-9 describes options that change statistics shown during top 's runtime.
Table 2-9. top Runtime Options
Option | Explanation |
|---|---|
A | This displays an "alternate" display of process information that shows top consumers of various system resources. |
I | This toggles whether top will divide the CPU usage by the number of CPUs on the system. |
For example, if a process was consuming all of both CPUs on a two-CPU system, this toggles whether top displays a CPU usage of 100% or 200%. | |
f | This displays a configuration screen that enables you to select which process statistics display on the screen. |
o | This displays a configuration screen that enables you to change the order of the displayed statistics. |
The options described in Table 2-10 turn on or off the display of various system-wide information. It can be helpful to turn off unneeded statistics to fit more processes on the screen.
Table 2-10. top Runtime Output Toggles
Option | Explanation |
|---|---|
1 (numeral 1) | This toggles whether the CPU usage will be broken down to the individual usage or shown as a total. |
l | This toggles whether the load average and uptime information will be updated and displayed. |
top v3.x provides system-wide information in addition to information about specific processes similar to those of top v2.x . These statistics are covered in Table 2-11.
Table 2-11. top Performance Statistics
Option | Explanation |
|---|---|
us | CPU time spent in user applications. |
sy | CPU time spent in the kernel. |
ni | CPU time spent in "nice"ed processes. |
id | CPU time spent idle. |
wa | CPU time spent waiting for I/O. |
hi | CPU time spent in the irq handlers. |
si | CPU time spent in the softirq handlers. |
load average | The 1-minute, 5-minute, and 15-minute load average. |
%CPU | The percentage of CPU that a particular process is consuming. |
PRI | The priority value of the process, where a higher value indicates a higher priority. RT indicates that the task has real-time priority, a priority higher than the standard range. |
NI | The nice value of the process. The higher the nice value, the less the system has to execute the process. Processes with high nice values tend to have very low priorities. |
WCHAN | If a process is waiting on an I/O, this shows which kernel function it is waiting in. |
TIME | The total amount CPU time (user and system) that this process has used since it started executing. |
COMMAND | That command that this process is executing. |
S | This is the current status of a process, where the process is either sleeping ( S ), running ( R ), zombied (killed but not yet dead) ( Z ), in an uninterruptable sleep ( D ), or being traced (T ). |
top provides a large amount of information about the different running processes and is a great way to figure out which process is a resource hog. The v.3 version of top has trimmed -down top and added some alternative views of similar data.
2.2.3.2 Example Usage
Listing 2.9 is an example run of top v3.0. Again, it will periodically update the screen until you exit it. The statistics are similar to those of top v2.x, but are named slightly differently.
Listing 2.9.
catan> top top - 08:52:21 up 19 days, 21:38, 17 users, load average: 1.06, 1.13, 1.15 Tasks: 149 total, 1 running, 146 sleeping, 1 stopped, 1 zombie Cpu(s): 0.8% us, 0.4% sy, 4.2% ni, 94.2% id, 0.1% wa, 0.0% hi, 0.3% si Mem: 1034320k total, 1023188k used, 11132k free, 39920k buffers Swap: 2040244k total, 214496k used, 1825748k free, 335488k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 26364 root 16 0 400m 68m 321m S 3.8 6.8 379:32.04 X 26737 ezolt 15 0 71288 45m 21m S 1.9 4.5 6:32.04 gnome-terminal 29114 ezolt 15 0 34000 22m 18m S 1.9 2.2 27:57.62 gnome-system-mo 9581 ezolt 15 0 2808 1028 1784 R 1.9 0.1 0:00.03 top 1 root 16 0 2396 448 1316 S 0.0 0.0 0:01.68 init 2 root RT 0 0 0 0 S 0.0 0.0 0:00.68 migration/0 3 root 34 19 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/0 4 root RT 0 0 0 0 S 0.0 0.0 0:00.27 migration/1 5 root 34 19 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/1 6 root RT 0 0 0 0 S 0.0 0.0 0:22.49 migration/2 7 root 34 19 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/2 8 root RT 0 0 0 0 S 0.0 0.0 0:37.53 migration/3 9 root 34 19 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/3 10 root 5 -10 0 0 0 S 0.0 0.0 0:01.74 events/0 11 root 5 -10 0 0 0 S 0.0 0.0 0:02.77 events/1 12 root 5 -10 0 0 0 S 0.0 0.0 0:01.79 events/2 Now pressing f while top is running brings the configuration screen shown in Listing 2.10. When you press the keys indicated (A for PID, B for PPID, etc.), top toggles whether these statistics display in the previous screen. When all the desired statistics are selected, press Enter to return totop 's initial screen, which now shows the current values of selected statistics. When you are configuring the statistics, all currently activated fields are capitalized in the Current Field Order line and have and asterisk (*) next to their name. Notice that most of statistics are similar, but the names have slightly changed.
Listing 2.10.
(press 'f' while running) Current Fields: AEHIOQTWKNMbcdfgjplrsuvyzX for window 1:Def Toggle fields via field letter, type any other key to return * A: PID = Process Id u: nFLT = Page Fault count * E: USER = User Name v: nDRT = Dirty Pages count * H: PR = Priority y: WCHAN = Sleeping in Function * I: NI = Nice value z: Flags = Task Flags <sched.h> * O: VIRT = Virtual Image (kb) * X: COMMAND = Command name/line * Q: RES = Resident size (kb) * T: SHR = Shared Mem size (kb) Flags field: * W: S = Process Status 0x00000001 PF_ALIGNWARN * K: %CPU = CPU usage 0x00000002 PF_STARTING * N: %MEM = Memory usage (RES) 0x00000004 PF_EXITING * M: TIME+ = CPU Time, hundredths 0x00000040 PF_FORKNOEXEC b: PPID = Parent Process Pid 0x00000100 PF_SUPERPRIV c: RUSER = Real user name 0x00000200 PF_DUMPCORE d: UID = User Id 0x00000400 PF_SIGNALED f: GROUP = Group Name 0x00000800 PF_MEMALLOC g: TTY = Controlling Tty 0x00002000 PF_FREE_PAGES (2.5) j: #C = Last used cpu (SMP) 0x00008000 debug flag (2.5) p: SWAP = Swapped size (kb) 0x00024000 special threads (2.5) l: TIME = CPU Time 0x001D0000 special states (2.5) r: CODE = Code size (kb) 0x00100000 PF_USEDFPU (thru 2.4) s: DATA = Data+Stack size (kb)
Listing 2.11 shows the new output mode of top , where many different statistics are sorted and displayed on the same screen.
Listing 2.11.
(press 'F' while running) 1:Def - 09:00:48 up 19 days, 21:46, 17 users, load average: 1.01, 1.06, 1.10 Tasks: 144 total, 1 running, 141 sleeping, 1 stopped, 1 zombie Cpu(s): 1.2% us, 0.9% sy, 0.0% ni, 97.9% id, 0.0% wa, 0.0% hi, 0.0% si Mem: 1034320k total, 1024020k used, 10300k free, 39408k buffers Swap: 2040244k total, 214496k used, 1825748k free, 335764k cached 1 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 29114 ezolt 16 0 34112 22m 18m S 3.6 2.2 28:15.06 gnome-system-mo 26364 root 15 0 400m 68m 321m S 2.6 6.8 380:01.09 X 9689 ezolt 16 0 3104 1092 1784 R 1.0 0.1 0:00.09 top 2 PID PPID TIME+ %CPU %MEM PR NI S VIRT SWAP RES UID COMMAND 30403 24989 0:00.03 0.0 0.1 15 0 S 5808 4356 1452 9336 bash 29510 29505 7:19.59 0.0 5.9 16 0 S 125m 65m 59m 9336 firefox-bin 29505 29488 0:00.00 0.0 0.1 16 0 S 5652 4576 1076 9336 run-mozilla.sh 3 PID %MEM VIRT SWAP RES CODE DATA SHR nFLT nDRT S PR NI %CPU COMMAND 8414 25.0 374m 121m 252m 496 373m 98m 1547 0 S 16 0 0.0 soffice.bin 26364 6.8 400m 331m 68m 1696 398m 321m 2399 0 S 15 0 2.6 X 29510 5.9 125m 65m 59m 64 125m 31m 253 0 S 16 0 0.0 firefox-bin 26429 4.7 59760 10m 47m 404 57m 12m 1247 0 S 15 0 0.0 metacity 4 PID PPID UID USER RUSER TTY TIME+ %CPU %MEM S COMMAND 1371 1 43 xfs xfs ? 0:00.10 0.0 0.1 S xfs 1313 1 51 smmsp smmsp ? 0:00.08 0.0 0.2 S sendmail 982 1 29 rpcuser rpcuser ? 0:00.07 0.0 0.1 S rpc.statd 963 1 32 rpc rpc ? 0:06.23 0.0 0.1 S portmap
top v3.x provides a slightly cleaner interface to top . It simplifies some aspects of it and provides a nice "summary" information screen that displays many of the resource consumers in the system.
2.2.4. procinfo (Display Info from the /proc File System)
Much like vmstat , procinfo provides a view of the system-wide performance characteristics. Although some of the information that it provides is similar to that of vmstat , it also provides information about the number of interrupts that the CPU received for each device. Its output format is a little more readable than vmstat , but it takes up much more screen space.
2.2.4.1 CPU Performance-Related Options
procinfo is invoked with the following command:
procinfo [-f] [-d] [-D] [-n sec] [-f file]
Table 2-12 describes the different options that change the output and the frequency of the samples that procinfo displays.
Table 2-12. procinfo Command-Line Options
Option | Explanation |
|---|---|
-f | Runs procinfo in full-screen mode |
-d | Displays statistics change between samples rather than totals |
-D | Displays statistic totals rather than rate of change |
-n sec | Number of seconds to pause between each sample |
-Ffile | Sends the output of procinfo to a file |
Table 2-13 shows the CPU statistics that procinfo gathers.
Table 2-13. procinfo CPU Statistics
Option | Explanation |
|---|---|
user | This is the amount of user time that the CPU has spent in days, hours, and minutes. |
nice | This is the amount of nice time that the CPU has spent in days, hours, and minutes. |
system | This is the amount of system time that the CPU has spent in days, hours, and minutes. |
idle | This is the amount of idle time that the CPU has spent in days, hours, and minutes. |
irq 0- N | This displays the number of the irq , the amount that has fired , and which kernel driver is responsible for it. |
Much like vmstat or top , procinfo is a low-overhead command that is good to leave running in a console or window on the screen. It gives a good indication of a system's health and performance.
2.2.4.2 Example Usage
Calling procinfo without any command options yields output similar to Listing 2.12. Without any options, procinfo displays only one screenful of status and then exits. procinfo is more useful when it is periodically updated using the -n second options. This enables you to see how the system's performance is changing in real time.
Listing 2.12.
[ezolt@scrffy ~/mail]$ procinfo Linux 2.4.18-3bigmem (bhcompile@daffy) (gcc 2.96 20000731 ) #1 4CPU [scrffy] Memory: Total Used Free Shared Buffers Cached Mem: 1030784 987776 43008 0 35996 517504 Swap: 2040244 17480 2022764 Bootup: Thu Jun 3 09:20:22 2004 Load average: 0.47 0.32 0.26 1/118 10378 user : 3:18:53.99 2.7% page in : 1994292 disk 1: 20r 0w nice : 0:00:22.91 0.0% page out: 2437543 disk 2: 247231r 131696w system: 3:45:41.20 3.1% swap in : 996 idle : 4d 15:56:17.10 94.0% swap out: 4374 uptime: 1d 5:45:18.80 context : 64608366 irq 0: 10711880 timer irq 12: 1319185 PS/2 Mouse irq 1: 94931 keyboard irq 14: 7144432 ide0 irq 2: 0 cascade [4] irq 16: 16 aic7xxx irq 3: 1 irq 18: 4152504 nvidia irq 4: 1 irq 19: 0 usb-uhci irq 6: 2 irq 20: 4772275 es1371 irq 7: 1 irq 22: 384919 aic7xxx irq 8: 1 rtc irq 23: 3797246 usb-uhci, eth0
As you can see from Listing 2.12, procinfo provides a reasonable overview of the system. We can see that, once again for the user, nice, system, and idle time, the system is not very busy. One interesting thing to notice is that procinfo claims that the system has spent more idle time than the system has been running (as indicated by the uptime). This is because the system actually has four CPUs, so for every day of wall time, four days of CPU time passes . The load average confirms that the system has been relatively work-free for the recent past. For the past minute, on the average, the system had less than one process ready to run; a load average of .47 indicates that a single process was ready to run only 47 percent of the time. On a four-CPU system, this large amount of CPU power is going to waste.
procinfo also gives us a good view of what devices on the system are causing interrupts. We can see that the Nvidia card ( nvidia ), IDE controller ( ide0 ), Ethernet device ( eth0 ), and sound card ( es1371 ) have a relatively high number of interrupts. This is as one would expect for a desktop workstation.
procinfo has the advantage of putting many of the system-wide performance statistics within a single screen, enabling you to see how the system is performing as a whole. It lacks details about network and disk performance, but it provide a good system-wide detail of the CPU and memory performance. One limitation that can be significant is the fact that procinfo does not report when the CPU is in the iowait , irq , orsoftirq mode.
2.2.5. gnome-system-monitor
gnome-system-monitor is, in many ways, a graphical counterpart of top . It enables you to graphically monitor individual processes and observe the load on the system based on the graphs that it displays.
2.2.5.1 CPU Performance-Related Options
gnome-system-monitor can be invoked from the Gnome menu. (Under Red Hat 9 and greater, this is under System Tools > System Monitor.) However, it can also be invoked using the following command:
gnome-system-monitor
gnome-system-monitor has no relevant command-line options that affect the CPU performance measurements. However, some of the statistics shown can be modified by selecting gnome-system-monitor's Edit > Preferences menu entry.
2.2.5.2 Example Usage
When you launch gnome-system-monitor , it creates a window similar to Figure 2-1. This window shows information about the amount of CPU and memory that a particular process is using. It also shows information about the parent/child relationships between each process.
Figure 2-1.
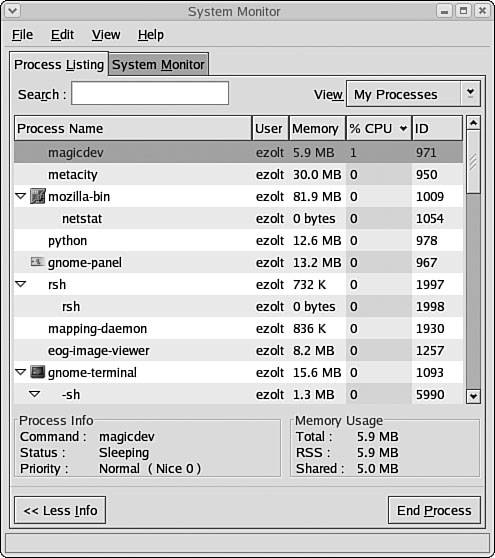
Figure 2-2 shows a graphical view of system load and memory usage. This is really what distinguishes gnome-system-monitor from top . You can easily see the current state of the system and how it compares to the previous state.
Figure 2-2.
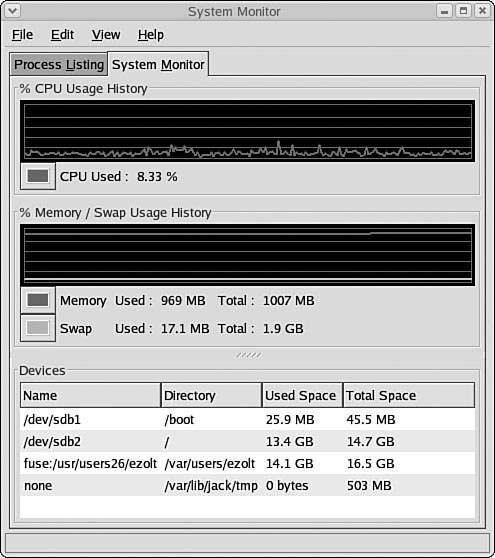
The graphical view of data provided by gnome-system-monitor can make it easier and faster to determine the state of the system, and how its behavior changes over time. It also makes it easier to navigate the system-wide process information.
2.2.6. mpstat (Multiprocessor Stat)
mpstat is a fairly simple command that shows you how your processors are behaving based on time. The biggest benefit of mpstat is that it shows the time next to the statistics, so you can look for a correlation between CPU usage and time of day.
If you have multiple CPUs or hyperthreading-enabled CPUs, mpstat can also break down CPU usage based on the processor, so you can see whether a particular processor is doing more work than the others. You can select which individual processor you want to monitor or you can askmpstat to monitor all of them.
2.2.6.1 CPU Performance-Related Options
mpstat can be invoked using the following command line:
mpstat [ -P { cpu | ALL } ] [ delay [ count ] ] Once again, delay specifies how often the samples will be taken, and count determines how many times it will be run. Table 2-14 describes the command-line options of mpstat .
Table 2-14. mpstat Command-Line Options
Option | Explanation |
|---|---|
-P { cpu | ALL } | This option tells mpstat which CPUs to monitor. cpu is the number between 0 and the total CPUs minus 1. |
delay | This specifies how long mpstat waits between samples. |
mpstat provides similar information to the other CPU performance tools, but it allows the information to be attributed to each of the processors in a particular system. Table 2-15 describes the options that it supports.
Table 2-15. mpstat CPU Statistics
Option | Explanation |
|---|---|
user | This is the percentage of user time that the CPU has spent during the previous sample. |
nice | This is the percentage of time that the CPU has spent during the previous sample running low-priority (or nice) processes. |
system | This is the percentage of system time that the CPU has spent during the previous sample. |
iowait | This is the percentage of time that the CPU has spent during the previous sample waiting on I/O. |
irq | This is the percentage of time that the CPU has spent during the previous sample handling interrupts. |
softirq | This is the percentage of time that the CPU has spent during the previous sample handling work that needed to be done by the kernel after an interrupt has been handled. |
idle | This is the percentage of time that the CPU has spent idle during the previous sample. |
mpstat is a good tool for providing a breakdown of how each of the processors is performing. Because mpstat provides a per-CPU breakdown, you can identify whether one of the processors is becoming overloaded.
2.2.6.2 Example Usage
First, we ask mpstat to show us the CPU statistics for processor number 0. This is shown in Listing 2.13.
Listing 2.13.
[ezolt@scrffy sysstat-5.1.1]$ ./mpstat -P 0 1 10 Linux 2.6.8-1.521smp (scrffy) 10/20/2004 07:12:02 PM CPU %user %nice %sys %iowait %irq %soft %idle intr/s 07:12:03 PM 0 9.80 0.00 1.96 0.98 0.00 0.00 87.25 1217.65 07:12:04 PM 0 1.01 0.00 0.00 0.00 0.00 0.00 98.99 1112.12 07:12:05 PM 0 0.99 0.00 0.00 0.00 0.00 0.00 99.01 1055.45 07:12:06 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1072.00 07:12:07 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1075.76 07:12:08 PM 0 1.00 0.00 0.00 0.00 0.00 0.00 99.00 1067.00 07:12:09 PM 0 4.90 0.00 3.92 0.00 0.00 0.98 90.20 1045.10 07:12:10 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1069.70 07:12:11 PM 0 0.99 0.00 0.99 0.00 0.00 0.00 98.02 1070.30 07:12:12 PM 0 3.00 0.00 4.00 0.00 0.00 0.00 93.00 1067.00 Average: 0 2.19 0.00 1.10 0.10 0.00 0.10 96.51 1085.34
Listing 2.14 shows a similar command on very unloaded CPUs that both have hyperthreading. You can see how the stats for all the CPUs are shown. One interesting observation in this output is the fact that one CPU seems to handle all the interrupts. If the system was heavy loaded with I/O, and all the interrupts were being handed by a single processor, this could be the cause of a bottleneck, because one CPU is overwhelmed, and the rest are waiting for work to do. You would be able to see this with mpstat, if the processor handling all the interrupts had no idle time, whereas the other processors did.
Listing 2.14.
[ezolt@scrffy sysstat-5.1.1]$ ./mpstat -P ALL 1 2 Linux 2.6.8-1.521smp (scrffy) 10/20/2004 07:13:21 PM CPU %user %nice %sys %iowait %irq %soft %idle intr/s 07:13:22 PM all 3.98 0.00 1.00 0.25 0.00 0.00 94.78 1322.00 07:13:22 PM 0 2.00 0.00 0.00 1.00 0.00 0.00 97.00 1137.00 07:13:22 PM 1 6.00 0.00 2.00 0.00 0.00 0.00 93.00 185.00 07:13:22 PM 2 1.00 0.00 0.00 0.00 0.00 0.00 99.00 0.00 07:13:22 PM 3 8.00 0.00 1.00 0.00 0.00 0.00 91.00 0.00 07:13:22 PM CPU %user %nice %sys %iowait %irq %soft %idle intr/s 07:13:23 PM all 2.00 0.00 0.50 0.00 0.00 0.00 97.50 1352.53 07:13:23 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 100.00 1135.35 07:13:23 PM 1 6.06 0.00 2.02 0.00 0.00 0.00 92.93 193.94 07:13:23 PM 2 0.00 0.00 0.00 0.00 0.00 0.00 101.01 16.16 07:13:23 PM 3 1.01 0.00 1.01 0.00 0.00 0.00 100.00 7.07 Average: CPU %user %nice %sys %iowait %irq %soft %idle intr/s Average: all 2.99 0.00 0.75 0.12 0.00 0.00 96.13 1337.19 Average: 0 1.01 0.00 0.00 0.50 0.00 0.00 98.49 1136.18 Average: 1 6.03 0.00 2.01 0.00 0.00 0.00 92.96 189.45 Average: 2 0.50 0.00 0.00 0.00 0.00 0.00 100.00 8.04 Average: 3 4.52 0.00 1.01 0.00 0.00 0.00 95.48 3.52
mpstat can be used to determine whether the CPUs are fully utilized and relatively balanced. By observing the number of interrupts each CPU is handling, it is possible to find an imbalance. Details on how to control where interrupts are routing are provided in the kernel source underDocumentation/IRQ-affinity.txt .
2.2.7. sar (System Activity Reporter)
sar has yet another approach to collecting system data. sar can efficiently record system performance data collected into binary files that can be replayed at a later date. sar is a low-overhead way to record information about how the system is performing.
The sar command can be used to record performance information, replay previous recorded information, and display real-time information about the current system. The output of the sar command can be formatted to make it easy to pipe to relational databases or to other Linux commands for processing.
2.2.7.1 CPU Performance-Related Options
sar can be invoked with the following command line:
sar [options] [ delay [ count ] ]
Although sar reports about many different areas of Linux, the statistics are of two different forms. One set of statistics is the instantaneous value at the time of the sample. The other is a rate since the last sample. Table 2-16 describes the command-line options of sar .
Table 2-16. sar Command-Line Options
Option | Explanation |
|---|---|
-c | This reports information about how many processes are being created per second. |
-I {irq | SUM | ALL | XALL } | This reports the rates that interrupts have been occurring in the system. |
-P {cpu | ALL } | This option specifies which CPU the statistics should be gathered from. If this isn't specified, the system totals are reported. |
-q | This reports information about the run queues and load averages of the machine. |
-u | This reports information about CPU utilization of the system. (This is the default output.) |
-w | This reports the number of context switches that occurred in the system. |
-o filename | This specifies the name of the binary output file that will store the performance statistics. |
-f filename | This specifies the filename of the performance statistics. |
delay | The amount of time to wait between samples. |
count | The total number of samples to record. |
sar offers a similar set (with different names) of the system-wide CPU performance statistics that we have seen in the proceeding tools. The list is shown in Table 2-17.
Table 2-17. sar CPU Statistics
Option | Explanation |
|---|---|
user | This is the percentage of user time that the CPU has spent during the previous sample. |
nice | This is the percentage of time that the CPU has spent during the previous sample running low-priority (or nice) processes. |
system | This is the percentage of system time that the CPU has spent during the previous sample. |
iowait | This is the percentage of time that the CPU has spent during the previous sample waiting on I/O. |
idle | This is the percentage of time that the CPU was idle during the previous sample. |
runq-sz | This is the size of the run queue when the sample was taken. |
plist -sz | This is the number of processes present (running, sleeping, or waiting for I/O) when the sample was taken. |
ldavg-1 | This was the load average for the last minute. |
ldavg-5 | This was the load average for the past 5 minutes. |
ldavg-15 | This was the load average for the past 15 minutes. |
proc/s | This is the number of new processes created per second. (This is the same as the forks statistic from vmstat .) |
cswch | This is the number of context switches per second. |
intr/s | The number of interrupts fired per second. |
One of the significant benefits of sar is that it enables you to save many different types of time-stamped system data to log files for later retrieval and review. This can prove very handy when trying to figure out why a particular machine is failing at a particular time.
2.2.7.2 Example Usage
This first command shown in Listing 2.15 takes three samples of the CPU every second, and stores the results in the binary file/tmp/apache_test . This command does not have any visual output and just returns when it has completed.
Listing 2.15.
[ezolt@wintermute sysstat-5.0.2]$ sar -o /tmp/apache_test 1 3
After the information has been stored in the /tmp/apache_test file, we can display it in various formats. The default is human readable. This is shown in Listing 2.16. This shows similar information to the other system monitoring commands, where we can see how the processor was spending time at a particular time.
Listing 2.16.
[ezolt@wintermute sysstat-5.0.2]$ sar -f /tmp/apache_test Linux 2.4.22-1.2149.nptl (wintermute.phil.org) 03/20/04 17:18:34 CPU %user %nice %system %iowait %idle 17:18:35 all 90.00 0.00 10.00 0.00 0.00 17:18:36 all 95.00 0.00 5.00 0.00 0.00 17:18:37 all 92.00 0.00 6.00 0.00 2.00 Average: all 92.33 0.00 7.00 0.00 0.67
However, sar can also output the statistics in a format that can be easily imported into a relational database, as shown in Listing 2.17. This can be useful for storing a large amount of performance data. Once it has been imported into a relational database, the performance data can be analyzedwith all of the tools of a relational database.
Listing 2.17.
[ezolt@wintermute sysstat-5.0.2]$ sar -f /tmp/apache_test -H wintermute.phil.org;1;2004-03-20 22:18:35 UTC;-1;90.00;0.00;10.00;0.00;0.00 wintermute.phil.org;1;2004-03-20 22:18:36 UTC;-1;95.00;0.00;5.00;0.00;0.00 wintermute.phil.org;1;2004-03-20 22:18:37 UTC;-1;92.00;0.00;6.00;0.00;2.00
Finally, sar can also output the statistics in a format that can be easily parsed by standard Linux tools such as awk, perl, python , orgrep . This output, which is shown in Listing 2.18, can be fed into a script that will pull out interesting events, and possibly even analyze different trends in the data.
Listing 2.18.
[ezolt@wintermute sysstat-5.0.2]$ sar -f /tmp/apache_test -h wintermute.phil.org 1 1079821115 all %user 90.00 wintermute.phil.org 1 1079821115 all %nice 0.00 wintermute.phil.org 1 1079821115 all %system 10.00 wintermute.phil.org 1 1079821115 all %iowait 0.00 wintermute.phil.org 1 1079821115 all %idle 0.00 wintermute.phil.org 1 1079821116 all %user 95.00 wintermute.phil.org 1 1079821116 all %nice 0.00 wintermute.phil.org 1 1079821116 all %system 5.00 wintermute.phil.org 1 1079821116 all %iowait 0.00 wintermute.phil.org 1 1079821116 all %idle 0.00 wintermute.phil.org 1 1079821117 all %user 92.00 wintermute.phil.org 1 1079821117 all %nice 0.00 wintermute.phil.org 1 1079821117 all %system 6.00 wintermute.phil.org 1 1079821117 all %iowait 0.00 wintermute.phil.org 1 1079821117 all %idle 2.00
In addition to recording information in a file, sar can also be used to observe a system in real time. In the example shown in Listing 2.19, the CPU state is sampled three times with one second between them.
Listing 2.19.
[ezolt@wintermute sysstat-5.0.2]$ sar 1 3 Linux 2.4.22-1.2149.nptl (wintermute.phil.org) 03/20/04 17:27:10 CPU %user %nice %system %iowait %idle 17:27:11 all 96.00 0.00 4.00 0.00 0.00 17:27:12 all 98.00 0.00 2.00 0.00 0.00 17:27:13 all 92.00 0.00 8.00 0.00 0.00 Average: all 95.33 0.00 4.67 0.00 0.00
The default display's purpose is to show information about the CPU, but other information can also be displayed. For example, sar can show the number of context switches per second, and the number of memory pages that have been swapped in or out. In Listing 2.20, sar samples the information two times, with one second between them. In this case, we ask sar to show us the total number of context switches and process creations that occur every second. We also ask sar for information about the load average. We can see in this example that this machine has 163 process that are in memory but not running. For the past minute, on average 1.12 processes have been ready to run.
Listing 2.20.
[ezolt@scrffy manuscript]$ sar -w -c -q 1 2 Linux 2.6.8-1.521smp (scrffy) 10/20/2004 08:23:29 PM proc/s 08:23:30 PM 0.00 08:23:29 PM cswch/s 08:23:30 PM 594.00 08:23:29 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 08:23:30 PM 0 163 1.12 1.17 1.17 08:23:30 PM proc/s 08:23:31 PM 0.00 08:23:30 PM cswch/s 08:23:31 PM 812.87 08:23:30 PM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 08:23:31 PM 0 163 1.12 1.17 1.17 Average: proc/s Average: 0.00 Average: cswch/s Average: 703.98 Average: runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 Average: 0 163 1.12 1.17 1.17
As you can see, sar is a powerful tool that can record many different performance statistics. It provides a Linux-friendly interface that enables you to easily extract and analyze the performance data.
2.2.8. oprofile
oprofile is a performance suite that uses the performance counter hardware available in nearly all modern processors to track where CPU time is being spent on an entire system, and individual processes. In addition to measuring where CPU cycles are spent, oprofile can measure very low-level information about how the CPU is performing. Depending on the events supported by the underlying processor, it can measure such things as cache misses, branch mispredictions and memory references, and floating-point operations.
oprofile does not record every event that occurs; instead, it works with the processor's performance hardware to sample every count events, where count is a value that users specify when they start oprofile . The lower the value of count , the more accurate the results are, but the higher the overhead of oprofile . By keeping count to a reasonable value, oprofile can run with a very low overhead but still give an amazingly accurate account of the performance of the system.
Sampling is very powerful, but be careful for some nonobvious gotchas when using it. First, sampling may say that you are spending 90 percent of your time in a particular routine, but it does not say why. There can be two possible causes for a high number of cycles attributed to a particular routine. First, it is possible that this routine is the bottleneck and is taking a long amount of time to execute. However, it may also be that the function is taking a reasonable amount of time to execute, but is called a large number of times. You can usually figure out which is the case by looking at the samples around, the particularly hot line, or by instrumenting the code to count the number of calls that are made to it.
The second problem of sampling is that you are never quite sure where a function is being called from. Even if you figure out that the function is being called many times and you track down all of the functions that call it, it is not necessarily clear which function is doing the majority of the calling.
2.2.8.1 CPU Performance-Related Options
oprofile is actually a suite of pieces that work together to collect CPU performance statistics. There are three main pieces of oprofile :
- The oprofile kernel module manipulates the processor and turns on and off sampling.
- The oprofile daemon collects the samples and saves them to disk.
- The oprofile reporting tools take the collected samples and show the user how they relate to the applications running on the system.
The oprofile suite hides the driver and daemon manipulation in the opcontrol command. The opcontrol command is used to select which events the processor will sample and start the sampling.
When controlling the daemon, you can invoke opcontrol using the following command line:
opcontrol [--start] [--stop] [--dump]
This option's control, the profiling daemon, enables you to start and stop sampling and to dump the samples from the daemon's memory to disk. When sampling, the oprofile daemon stores a large amount of samples in internal buffers. However, it is only possibly to analyze the samples that have been written (or dumped) to disk. Writing to disk can be an expensive operation, so oprofile only does it periodically. As a result, after running a test and profiling with oprofile , the results may not be available immediately, and you will have to wait until the daemon flushes the buffers to disk. This can be very annoying when you want to begin analysis immediately, so the opcontrol command enables you to force the dump of samples from the oprofile daemon's internal buffers to disk. This enables you to begin a performance investigation immediately after a test has completed.
Table 2-18 describes the command-line options for the opcontrol program that enable you to control the operation of the daemon.
Table 2-18. opcontrol Daemon Control
Option | Explanation |
|---|---|
-s/--start | Starts profiling unless this uses a default event for the current processor |
-d/--dump | Dumps the sampling information that is currently in the kernel sample buffers to the disk. |
--stop | This will stop the profiling. |
By default, oprofile picks an event with a given frequency that is reasonable for the processor and kernel that you are running it on. However, it has many more events that can be monitored than the default. When you are listing and selecting an event, opcontrol is invoked using the following command line:
opcontrol [--list-events] [-event=:name:count:unitmask:kernel:user:]
The event specifier enables you to select which event is going to be sampled; how frequently it will be sampled; and whether that sampling will take place in kernel space, user space, or both. Table 2-19 describes the command-line option of opcontrol that enables you to select different events to sample.
Table 2-19. opcontrol Event Handling
Option | Explanation |
|---|---|
-l/--list-events | Lists the different events that the processor can sample. |
-event=:name:count: unitmask:kernel:user: | Used to specify what events will be sampled. The event name must be one of the events that the processor supports. A valid event can be retrieved from the --list- events option. The count parameter specifies that the processor will be sampled every count times that event happens. The unitmask modifies what the event is going to sample. For example, if you are sampling "reads from memory," the unit mask may allow you to select only those reads that didn't hit in the cache. The kernel parameter specifies whether oprofile should sample when the processor is running in kernel space. The userparameter specifies whether oprofile should sample when the processor is running in user space. |
--vmlinux = kernel | Specifies which uncompressed kernel image oprofile will use to attribute samples to various kernel functions. |
After the samples have been collected and saved to disk, oprofile provides a different tool, opreport , which enables you to view the samples that have been collected. opreport is invoked using the following command line:
opreport [-r] [-t]
Typically, opreport displays all the samples collected by the system and which executables (including the kernel) are responsible for them. The executables with the highest number of samples are shown first, and are followed by all the executables with samples. In a typical system, most of the samples are in a handful of executables at the top of the list, with a very large number of executables contributing a very small number of samples. To deal with this, opreport enables you to set a threshold, and only executables with that percentage of the total samples or greater will be shown. Alternatively, opreport can reverse the order of the executables that are shown, so those with a high contribution are shown last. This way, the most important data is printed last, and it will not scroll off the screen.
Table 2-20 describes these command-line options of opreport that enable you to format the output of the sampling.
Table 2-20. opreport Report Format
Option | Explanation |
|---|---|
--reverse-sort / -r | Reverses the order of the sort. Typically, the images that caused the most events display first. |
--threshold / -t [percentage] | Causes opreport to only show images that havecontributed percentage or more amount of samples. This can be useful when there are many images with a very small number of samples and you are only interested in the most significant. |
Again, oprofile is a complicated tool, and these options show only the basics of what oprofile can do. You learn more about the capabilities of oprofile in later chapters.
2.2.8.2 Example Usage
oprofile is a very powerful tool, but it can also be difficult to install. Appendix B, "Installing oprofile," contains instructions on how to getoprofile installed and running on a few of the major Linux distributions.
We begin the use of oprofile by setting it up for profiling. This first command, shown in Listing 2.21, uses the opcontrol command to tell the oprofile suite where an uncompressed image of the kernel is located. oprofile needs to know the location of this file so that it can attribute samples to exact functions within the kernel.
Listing 2.21.
[root@wintermute root]# opcontrol --vmlinux=/boot/vmlinux-\ 2.4.22-1.2174.nptlsmp
After we set up the path to the current kernel, we can begin profiling. The command in Listing 2.22 tells oprofile to start sampling using the default event. This event varies depending on the processor, but the default event for this processor is CPU_CLK_UNHALTED . This event samples all of the CPU cycles where the processor is not halted. The 233869 means that the processor will sample the instruction the processor is executing every 233,869 events.
Listing 2.22.
[root@wintermute root]# opcontrol -s Using default event: CPU_CLK_UNHALTED:233869:0:1:1 Using log file /var/lib/oprofile/oprofiled.log Daemon started. Profiler running.
Now that we have started sampling, we want to begin to analyze the sampling results. In Listing 2.23, we start to use the reporting tools to figure out what is happening in the system. opreport reports what has been profiled so far.
Listing 2.23.
[root@wintermute root]# opreport opreport op_fatal_error: No sample file found: try running opcontrol --dump or specify a session containing sample files
Uh oh! Even though the profiling has been happening for a little while, we are stopped when opreport specifies that it cannot find any samples. This is because the opreport command is looking for the samples on disk, but the oprofile daemon stores the samples in memory and only periodically dumps them to disk. When we ask opreport for a list of the samples, it does not find any on disk and reports that it cannot find any samples. To alleviate this problem, we can force the daemon to flush the samples immediately by issuing a dump option to opcontrol , as shown in Listing 2.24. This command enables us to view the samples that have been collected.
Listing 2.24.
[root@wintermute root]# opcontrol --dump
After we dump the samples to disk, we try again, and ask oprofile for the report, as shown in Listing 2.25. This time, we have results. The report contains information about the processor that it was collected on and the types of events that were monitored. The report then lists in descending order the number of events that occurred and which executable they occurred in. We can see that the Linux kernel is taking up 50 percent of the total cycles, emacs is taking 14 percent, and libc is taking 12 percent. It is possible to dig deeper into executable and determine which function is taking up all the time, but that is covered in Chapter 4, "Performance Tools: Process-Specific CPU."
Listing 2.25.
[root@wintermute root]# opreport CPU: PIII, speed 467.739 MHz (estimated) Counted CPU_CLK_UNHALTED events (clocks processor is not halted) with a unit mask of 0x00 (No unit mask) count 233869 3190 50.4507 vmlinux-2.4.22-1.2174.nptlsmp 905 14.3128 emacs 749 11.8456 libc-2.3.2.so 261 4.1278 ld-2.3.2.so 244 3.8589 mpg321 233 3.6850 insmod 171 2.7044 libperl.so 128 2.0244 bash 113 1.7871 ext3.o ....
When we started the oprofile , we just used the default event that opcontrol chose for us. Each processor has a very rich set of events that can be monitored. In Listing 2.26, we ask opcontrol to list all the events that are available for this particular CPU. This list is quite long, but in this case, we can see that in addition to CPU_CLK_UNHALTED , we can also monitor DATA_MEM_REFS and DCU_LINES_IN . These are memory events caused by the memory subsystem, and we investigate them in later chapters.
Listing 2.26.
[root@wintermute root]# opcontrol -l oprofile: available events for CPU type "PIII" See Intel Architecture Developer's Manual Volume 3, Appendix A and Intel Architecture Optimization Reference Manual (730795-001) CPU_CLK_UNHALTED: (counter: 0, 1) clocks processor is not halted (min count: 6000) DATA_MEM_REFS: (counter: 0, 1) all memory references, cachable and non (min count: 500) DCU_LINES_IN: (counter: 0, 1) total lines allocated in the DCU (min count: 500) ....
The command needed to specify which events we will monitor can be cumbersome, so fortunately, we can also use oprofile 's graphicaloprof_start command to graphically start and stop sampling. This enables us to select the events that we want graphically without the need to figure out the exact way to specify on the command line the events that we want to monitor.
In the example of op_control shown in Figure 2-3, we tell oprofile that we want to monitor DATA_MEM_REFS and L2_LD events at the same time. The DATA_MEM_REFS event can tell us which applications use the memory subsystem a lot and which use the level 2 cache. In this particular processor, the processor's hardware has only two counters that can be used for sampling, so only two events can be used simultaneously .
Figure 2-3.
Now that we have gathered the samples using the graphical interface to operofile , we can now analyze the data that it has collected. In Listing 2.27, we ask opreport to display the profile of samples that it has collected in a similar way to how we did when we were monitoring cycles. In this case, we can see that the libmad library has 31 percent of the data memory references of the whole system and appears to be the heaviest user of the memory subsystem.
Listing 2.27.
[root@wintermute root]# opreport CPU: PIII, speed 467.739 MHz (estimated) Counted DATA_MEM_REFS events (all memory references, cachable and non) with a unit mask of 0x00 (No unit mask) count 30000 Counted L2_LD events (number of L2 data loads) with a unit mask of 0x0f (All cache states) count 233869 87462 31.7907 17 3.8636 libmad.so.0.1.0 24259 8.8177 10 2.2727 mpg321 23735 8.6272 40 9.0909 libz.so.1.2.0.7 17513 6.3656 56 12.7273 libgklayout.so 17128 6.2257 90 20.4545 vmlinux-2.4.22-1.2174.nptlsmp 13471 4.8964 4 0.9091 libpng12.so.0.1.2.2 12868 4.6773 20 4.5455 libc-2.3.2.so ....
The output provided by opreport displays all the system libraries and executables that contain any of the events that we were sampling. Note that not all the events have been recorded; because we are sampling, only a subset of events are actually recorded. This is usually not a problem, because if a particular library or executable is a performance problem, it will likely cause high-cost events to happen many times. If the sampling is random, these high-cost events will eventually be caught by the sampling code.
No comments:
Post a Comment